I come at these sorts of analyses totally primed for confirmation bias, but I really enjoyed this critical view of “Radnet: The AI Story That Doesn’t Add Up,” published by Hunterbrook. The authors argue that:
-
RadNet’s much-hyped AI business is a sideshow
-
The success of RadNet’s roll up business is also misunderstood
-
The truth is buried beneath inconsistent disclosures.
-
That “RadNet’s soaring stock relies” on “manufactured profits” based on “adjusted margins that strip out both stock-based compensation and some R&D spending”
-
Insiders are cashing out. Over the past two years, RadNet insiders have sold more than 780,000 shares — worth $50.9 million — without any open-market purchases.
It’s a good read.
AI is real, but it doesn’t mean there isn’t a lot of BS and plenty of companies that are going to lose badly. The touted growth of RadNet’s AI business appears, unsurprisingly, “to come from sales to its own imaging centers.” Even when it bought a real company with customers like iCAD, folks were immediately less interested:
That friction played out in real time after the iCAD acquisition. Before the deal, iCAD counted SimonMed, one of the country’s largest imaging chains, which now sells Mammogram+, as a critical customer. Yet almost immediately after RadNet announced the buyout, SimonMed signed on with a different provider, Lunit. The message was clear: RadNet’s potential customers for its DeepHealth business view the company as a predator, not a partner.
No one wants to help a predator by using their software, whether that’s RadNet or Radiology Partners. Since companies that don’t compete directly also make radiology software, the practical addressable market is far smaller than the total market (as long as these guys don’t have something truly unique, truly better, and, ideally, also cheaper).
Then, some of the reported same-center growth appears to actually be the closure and combination of nearby centers. Owning an imaging center can still be a good business, but perhaps consolidation and scale didn’t bring the magical efficiencies folks were hoping for. The roll-up primarily makes it easier for bigger players to buy what used to be a bunch of small businesses; it is, in many cases, a capital game more than an operational one.
RadNet may have a valid business case for closing a center and consolidating, but the move plays havoc with same-center sales math. Imagine two centers, A and B, five minutes apart. Each does $3 million in revenue. Together, they make $6 million in a year. If demand is flat, the next year they’ll still make $6 million. The same-center growth is zero.
Now, say that RadNet closes center B and routes its patients to A. B is gone from the same-center calculation — but its revenue has simply shifted to A, the RadNet location a few minutes away.
So A can show 100% same-center sales growth, thereby helping to drive up the company’s average. But nothing fundamental happened. This isn’t DeepHealth helping RadNet get more business. The volume didn’t grow, it merely changed addresses.
The article goes on. Again, perhaps overly credulous as I am about companies being dishonest to investors and the public, I find this compelling reporting.
One of the greatest issues with stock-based compensation and bonuses is the outsized incentive to make money on short-term storytelling or through other questionable means, even when it’s bullshit or when you are mismanaging the actual business. Over the past few years, slap AI on something middling, and even if it’s vaporware or commoditized features, as long as somebody buys your stock after the story +/- dubious financial accounting maneuvers, you can sell your stock and make your money.
When the article was published in December 2025, RadNet was trading at a serious premium thanks to this AI narrative. It has since fallen:
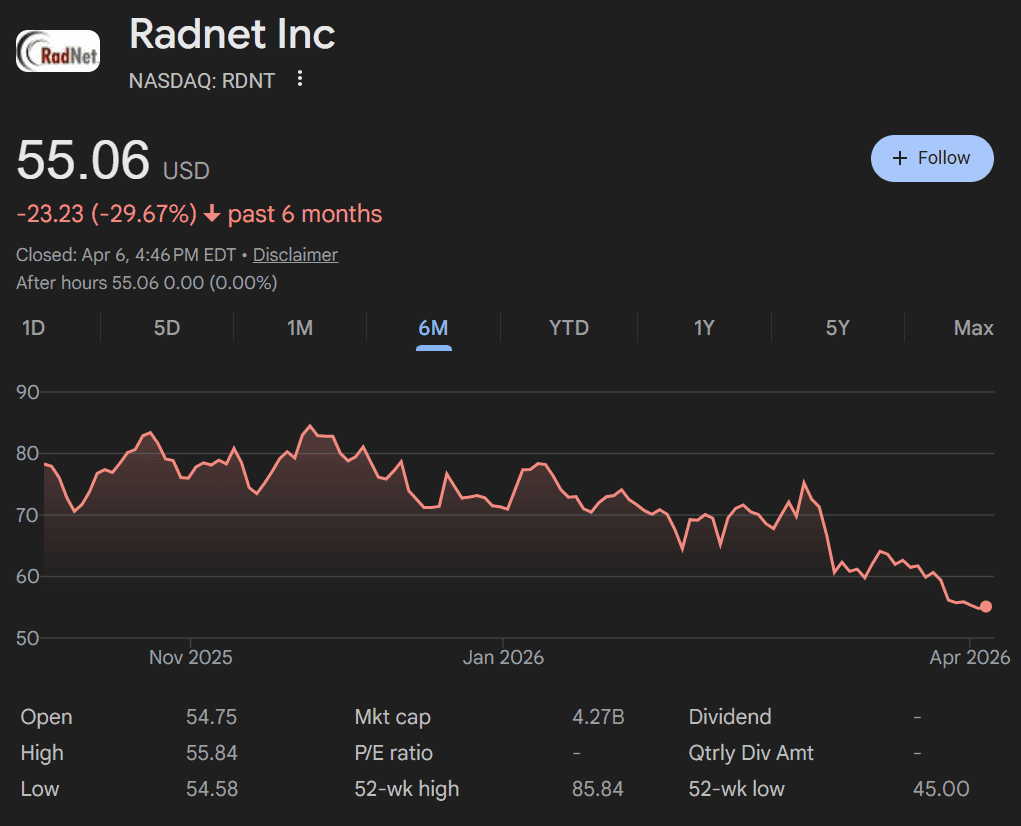
Seems like at least this specific AI narrative bubble is popping, but not before insiders sold a bunch of inflated stock and probably won the game they were playing.